
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- VLD
- Intel OpenCL
- Memory Leak
- OpenCL 2.0 시작하기
- 메모리 누수
- Kernel
- initialize
- Queue
- init
- Device
- Platform
- OpenCL 초기화
- OpenCL 2.0
- OpenCL
- Visual Leak Detector
- OpenCL 설치
- program
- Today
- Total
목록분류 전체보기 (24)
후로링의 프로그래밍 이야기
 #2 DeepStream 다짜고짜 실행해보기 - 2
#2 DeepStream 다짜고짜 실행해보기 - 2
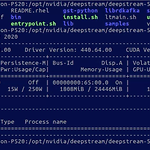
1. 컨테이너 실행해보기 Nvidia docker가 익숙하지 않으신 분들을 위해 커맨드와 간략한 설명을 남깁니다. nvidia-docker run -it -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -w /opt/nvidia/deepstream/deepstream-5.0 --net="host" --name=deepstream_test nvcr.io/nvidia/deepstream:5.0.1-20.09-triton /bin/bash - nvidia-docker run 으로 실행 할 수도있고, docker run --gpus all 로 실행 할 수도 있습니다. - "-it" 옵션은 컨테이너에 터미널 입력을 사용하기위한 옵션입니다. - "-v /tmp/.X11..
 #2 DeepStream 다짜고짜 실행해보기 - 1
#2 DeepStream 다짜고짜 실행해보기 - 1
일단 실행해서 비디오를 분석하는것을 보고 각종 코드, 플러그인에 대해 설명해 보겠습니다. DeepStream에 들어가는 각종 프레임워크를 코드단계에서 빌드하는것은 쉬운 일이 아닙니다. 따라서 Container를 활용 하도록 하겠습니다. 제 호스트환경은 Ubuntu 16.04이며 Nvidia-docker가 깔리는 환경이라면 Ubuntu 18.04, CentOS등 어떤 OS를 사용하셔도 상관 없습니다. 1. NGC - NGC Container registry : ngc.nvidia.com/catalog/containers/nvidia:deepstream NVIDIA NGC ngc.nvidia.com Nvidia에서 개발한 각종 프레임워크, SDK등의 컨테이너를 NGC에서 다운 받을 수 있습니다. 만약 회원가..
 #1 DeepStream Introduction
#1 DeepStream Introduction
1. DeepStream이란 딥러닝은 이미 너무나 보편화된 기술이 되었습니다. 관심이 있는 사람이라면 누구나 자신의 어플리케이션이 딥러닝 모델을 사용 해 여러 기능을 넣을 수 있습니다. 하지만, 딥러닝을 이용한 서비스는 비용이 비쌉니다. 비싼 GPU서버를 유지해야 하며, 사용한다고 하더라도 많은 서비스를 돌릴 수 없습니다. 이를 위해 다양한 배치처리, 모델 경량화 방법들이 연구되어왔고 적용되었지만 아직도 딥러닝은 너무 비싼 기술입니다. DeepStream은 비디오 분석 분야에서 높은 코스트를 가지는 딥러닝 분석을 사용할 수 있도록 NVIDIA에서 제작한 SDK입니다. 정확하게는 GStreamer 파이프라인 내에서 GPU관련된 디코딩/추론등을 수행할 수 있는 플러그인을 제작해 집어 넣은 것이라고 볼 수 있..
 Snorkel: Rapid Training Data Creation with Weak Supervision(Stanford DAWN, AAAI 2019)
Snorkel: Rapid Training Data Creation with Weak Supervision(Stanford DAWN, AAAI 2019)
최근 semi-supervised learning에서 data augmentation을 사용한 contrastive learning방법이 대세이기는 하지만, 실제 필드에서 새로 얻어지는 데이터에 대해 학습을 수행하고 싶을 때 가장 걸림돌이 되는 부분은 새로 얻은 데이터에 대한 labeling입니다. 이 논문에서는 서로 연관성이 있는 labeling model여러개를 조합하여 신뢰성이 높은 weak label을 생성하는 방법에 대해 설명하고 있습니다. 사람은 어떤 물체를 판단할때 하나의 knowledge만 가지고 판단하지 않습니다. 물론 눈에 보이는것이 가장 크기는 하지만 여러가지 정보를 조합해 사과를 사과다, 강아지를 강아지다 라고 판단합니다. 현재의 image classification이나 object..
 Scanner: Efficient Video Analysis at Scale (Stanford DAWN project, )
Scanner: Efficient Video Analysis at Scale (Stanford DAWN project, )
Stanford DAWN프로젝트는 제가 가장 좋아하는 연구실? 연구프로젝트? 이며, 데이터를 어떻게 다루는지에 대한 좋은 논문을 많이 내고 있습니다. ML architecture를 이용한 성능 향상이 한계에 봉착한 지금, 데이터를 이용한 성능 향상에 대한 논문이 많이 나오고 있는데, 2~3년 전부터 이와 관련된 논문을 꾸준히 내고 있는 곳입니다. 혹시나 비디오 관련 big data system을 고려하고 있다면 한번쯤은 봐야 할 논문이라고 생각합니다. 단순히 제가 논문을 한글로 line-by-line 으로 번역한 내용이지만 나름대로 이해를 하면서 써놓았기 때문에 읽으시는데 어려움이 없었으면 좋겠습니다.
 A Simple Framework for Contrastive Learning of Visual Representations (SimCLR), google research, 2020
A Simple Framework for Contrastive Learning of Visual Representations (SimCLR), google research, 2020
ImageNet의 Semi-supervised Learning 부분에서 최근 SOTA를 달성한 학습 방법으로, Positive pair을 이용한 Contrastive learning, Data-augmentation기법에 대한 좋은 insight를 얻을 수 있습니다. arxiv 주소 : arxiv.org/abs/2002.05709 A Simple Framework for Contrastive Learning of Visual Representations This paper presents SimCLR: a simple framework for contrastive learning of visual representations. We simplify recently proposed contrastive s..
 Tensorflow serving introduction
Tensorflow serving introduction
이 글은 기본적으로 Tensorflow에 대한 이해(Tensorflow Detection API를 통해 이미지 Inference를 해봤으며, 간단한 mnist tutorial정도는 이해할 수 있는 정도)가 있어야 진행이 가능하기때문에 인터넷상의 여러 자료들을 보며 같이 공부하거나 공부한 후에 보시면 좋을것 같습니다! Tensorflow? Tensorflow란 데이터의 흐름을 표현하기 위한 라이브러리 입니다. 일반적으로 딥러닝을 활용하기위해 많이 사용하게 됩니다. Python, C, Java script등 대부분의 언어를 지원하며 이와같은 특성 때문에 PC, 모바일 기기를 모두 지원하는 범용성이 높은 라이브러리 입니다. 또한 많은 Third parth에서 지원하고 있으며, Azure, GCP, AWS등 p..
Vtune Amplifier Vtune AMplifier는 프로세서의 성능을 분석하기 위한 도구입니다. CPU에서 돌아가는 기본적인 프로그램 뿐만 아니라 내장 GPU에서 돌아가는 OpenCL프로그램의 각 함수, 커널에 대해서 분석이 가능합니다. 홈페이지 주소 : https://software.intel.com/en-us/intel-vtune-amplifier-xe다운로드 링크 : https://software.intel.com/en-us/intel-vtune-amplifier-xe/try-buy기본적으로 1000달러 정도 하는 비싼 프로그램이지만 고맙게도 이메일 인증만 하면 30일 무료버전을 사용 하실 수 있습니다. 여건이 되는 회사나 연구실에서는 30일 이후에 구매하셔서 사용하시면 되고, 여건이 안되는..
비교기반의 정렬알고리즘은 어떤 경우에도 O(n logn)보다 빠를 수 없습니다. 이를 증명하하는것으로 Sorting 부분은 넘어가도록 하겠습니다. Insertion Sort, Heap Sort, Quick Sort, Counting Sort, Radix Sort, Bucket Sort등등은 인터넷상에 자료가 많습니다. 혹시라도 잘 모르시는분들은 찾아서 해보시면 되겠습니다. Sort가 진행되는 과정은 Decision Tree로 나타낼 수 있습니다. 증명에는 몇가지 Lemma(참으로 증명된 정리)가 필요합니다. 1. 모든 정렬 알고리즘의 decision tree는 n!개의 Permutation(순열)을 가진다. (다시말해, 정렬이 될 수 있는 모든 경우의 수가 n!이란 뜻입니다. ) 2. Binary tre..
 #4 알고리즘 Advanced Data Structure : Binomial Heap
#4 알고리즘 Advanced Data Structure : Binomial Heap
Binomial Heap을 배우기 위해서 Binomial Tree가 어떤 것인지 부터 알아보겠습니다. Binomial Tree Binomial Tree는 우선순위 큐 형태의 자료구조입니다. 아래 그림과 같이 한 Tree의 루트 노드가 다른 루트 노드를 가리키는 형태입니다. 노드의 수는 2^k(루트에 새로 붙여지는 트리와 붙는 트리의 크기가 같다), 루트에 붇기 때문에 높이는 1씩 증가하게되며 트리의 깊이는 K combination i(K에서 i를 뽑는 경우의수), 그리고 루트의 degree가 가장 크게 됩니다. Binomial Heap Binomial Heap의 각각의 Binomial Tree는 min-heap입니다. 그리고 k값이 같은 Binomial Tree는 존재하지 않습니다(차수가 같은 트리가 존..